stanford并行程序设计asset1:四核CPU性能分析
概述
本作业旨在帮助你理解现代多核CPU中的两种主要并行执行形式:
- 单个处理核心内的SIMD执行
- 使用多个核心的并行执行(你还会看到Intel超线程的效果)
你还将获得测量和分析并行程序性能的经验(这是一个具有挑战性但重要的技能,你将在本课程中多次使用)。这个作业涉及少量的编程,但需要大量的分析!
环境设置
你需要在新的myth机器上运行代码来完成这个作业
(这些机器的主机名为myth[51-66].stanford.edu)。如果因为某些原因你在myth机器上没有主目录,请在这里提交一个HelpSU票据。
这些机器包含四核4.2 GHz的Intel Core i7处理器(尽管动态频率缩放可以在芯片认为有用且可能的情况下将其提升到4.5 GHz)。处理器中的每个核心支持两个硬件线程(Intel称之为“超线程”),并且这些核心可以执行AVX2向量指令,这些指令描述了对多个单精度数据值执行相同的八宽操作。对于好奇的人,可以在https://ark.intel.com/products/97129/Intel-Core-i7-7700K-Processor-8M-Cache-up-to-4-50-GHz-找到这个CPU的完整规格。想深入了解的学生可能会喜欢这篇文章。
注意:为了评分目的,我们希望你报告在Stanford的myth机器上运行代码的性能,然而,你也可以在自己的机器上运行这些作业中的程序(你首先需要安装Intel SPMD程序编译器(ISPC),可以在http://ispc.github.io/找到)。如果你在其他机器上运行代码,也可以在报告中包含你的发现,只需非常清楚地说明你在哪台机器上运行。
开始:
- 需要安装ISPC来编译用于这个作业的许多程序。ISPC可以通过以下步骤在myth机器上轻松安装:
从myth机器上,在你选择的本地目录中下载linux二进制文件。你可以从ISPC的下载页面获取Linux的ISPC编译器二进制文件。从myth上,我们建议你使用wget直接从下载页面下载二进制文件。截至2023年秋季第一周,下面的wget行是有效的:
wget https://github.com/ispc/ispc/releases/download/v1.21.0/ispc-v1.21.0-linux.tar.gz
解压下载的文件:tar -xvf ispc-v1.21.0-linux.tar.gz
将ISPC的bin目录添加到你的系统路径。例如,如果解压文件生成了目录~/Downloads/ispc-v1.21.0-linux,在bash中你可以用以下命令更新你的路径变量:
export PATH=$PATH:${HOME}/Downloads/ispc-v1.21.0-linux/bin
可以将上述行添加到你的.bashrc文件中以使其永久生效。
如果你使用csh,可以使用setenv更新你的PATH。一个快速的Google搜索可以教你如何做。
作业的起始代码在https://github.com/stanford-cs149/asst1上可用。请使用以下命令克隆作业1的起始代码:
git clone https://github.com/stanford-cs149/asst1.git
程序1:使用线程并行生成分形(20分)
在代码库的prog1_mandelbrot_threads/目录中构建并运行代码。(输入make来构建,输入./mandelbrot来运行它。)这个程序生成图像文件mandelbrot-serial.ppm,这是一个称为Mandelbrot集合的著名复数集的可视化。大多数平台都有.ppm查看器。要远程查看生成的图像,首先确保你有_X服务器_。Linux系统不需要下载任何软件。然而,Mac用户可以使用Xquartz,Windows用户可以使用VcXsrv。在你获得SSH X转发支持后,确保你使用ssh -Y连接到myth机器,然后你可以使用display命令查看图像。如下面的图像所示,结果是一个熟悉且美丽的分形。图像中的每个像素对应于复平面中的一个值,每个像素的亮度与确定该值是否包含在Mandelbrot集合中的计算成本成正比。要获得图像2,请使用命令选项--view 2。(见mandelbrotSerial.cpp中定义的函数mandelbrotSerial())。你可以在http://en.wikipedia.org/wiki/Mandelbrot_set了解更多关于Mandelbrot集合的定义。

你的任务是使用std::thread并行化图像的计算。起始代码在mandelbrotThread.cpp中的函数mandelbrotThread()中生成了一个额外的线程。在这个函数中,主应用程序线程使用构造函数std::thread(function, args...)创建另一个线程。它通过调用线程对象上的join等待这个线程完成。目前启动的线程没有进行任何计算,并立即返回。你应该添加代码到workerThreadStart函数来完成这个任务。你不需要在这个作业中使用任何其他std::thread API调用。
你需要做的是:
- 修改起始代码,使用两个处理器并行生成Mandelbrot图像。具体来说,在线程0中计算图像的上半部分,在线程1中计算图像的下半部分。这种问题分解类型称为_空间分解_,因为图像的不同空间区域由不同的处理器计算。
- 扩展你的代码,使用2、3、4、5、6、7和8个线程,相应地分配图像生成工作(线程应获得图像的块)。注意,处理器只有四个核心,但每个核心支持两个超线程,所以它可以在其执行内容上交错执行总共八个线程。在你的报告中,生成__与参考顺序实现相比的加速图表__,作为所用线程数量的函数__对于视图1__。加速是否与所用线程数量呈线性关系?在你的报告中假设为什么会(或不会)这样?(你可能还希望为视图2生成一个图表,以帮助你提出一个好的答案。提示:仔细看看三线程的数据点。)
- 为了确认(或推翻)你的假设,通过在
workerThreadStart()的开始和结束插入计时代码来测量每个线程完成其工作的时间。你的测量结果如何解释你之前创建的加速图表? - 修改工作到线程的映射,以在__两个视图上获得大约7-8倍的加速__(如果超过7倍,那就可以了,不要担心)。你不能在你的解决方案中使用任何线程间的同步。我们期望你提出一个适用于所有线程数的单一工作分配策略——不允许对每个配置进行特定的硬编码解决方案!(提示:有一个非常简单的静态分配可以实现这个目标,并且不需要在线程之间进行通信/同步。)在你的报告中描述你的并行化方法,并报告最终获得的8线程加速。
- 现在用16个线程运行你的改进代码。性能是否明显比使用八个线程时更高?为什么或为什么不?
我的实现
(1)代码如下:
1 | void workerThreadStart(WorkerArgs * const args) { |
(2)加速比图表:
| 线程数 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 加速比 | 1.98 | 1.63 | 2.44 | 2.48 | 3.25 | 3.38 | 3.92 |
一般来说,线程越多,程序运行速度越快。然而,对于k个线程,程序的运行速度并没有提高k倍。我认为原因是线程之间的工作负载不平衡。在这个实现中,如果threadnum是k,那么图片水平分成k个块,线程i负责第i个块。在三个线程和视图1的情况下,中间的行(有更多的白色部分)需要更多的计算,所以第二个线程比其他两个线程运行得慢得多,甚至比两个线程——视图1的情况下的线程还要慢。这解释了上图中2和3之间的下降。
(3)
测量时间如下:
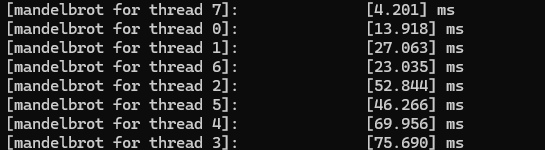
对于视图1,我们可以看到处理中间行(线程2、5、4、3)的线程比其他线程运行得慢得多。
(4)并行化方法:解决方法很简单,如果线程数是n,线程I负责图片的k * n + I行。
代码:
1 | void mandelbrotStepSerial( |
运行结果:

加速比为6.88
(5)
使用16线程运行代码:

加速比为 11.48 ,性能比8线程要好,因为线程数是其两倍
程序2:使用SIMD内在函数进行向量化代码(20分)
查看Assignment 1代码库的prog2_vecintrin/main.cpp中的clampedExpSerial函数。clampedExp()函数将values[i]提升到由exponents[i]给定的幂,并将结果值限制在9.999999。在程序2中,你的任务是向量化这段代码,使其可以在具有SIMD向量指令的机器上运行。
然而,与其使用映射到现代CPU上真实SIMD向量指令的SSE或AVX2向量内在函数,为了让事情更容易一些,我们要求你
使用CS149的“伪向量内在函数”来实现你的版本,这些函数定义在CS149intrin.h中。CS149intrin.h库为你提供了一组操作向量值和/或向量掩码的向量指令。(这些函数不会转换为真实的CPU向量指令,而是我们在库中模拟这些操作,并提供便于调试的反馈。)作为使用CS149内在函数的示例,main.cpp中给出了一个向量化版本的abs()函数。这个示例包含了一些基本的向量加载和存储,并操纵掩码寄存器。注意,abs()示例只是一个简单的例子,事实上代码并不能正确处理所有输入!(我们会让你来弄清楚为什么!)你可能希望阅读CS149intrin.h中的所有注释和函数定义,以了解有哪些操作可供使用。
以下是一些提示,帮助你实现:
- 每个向量指令都有一个可选的掩码参数。掩码参数定义了哪些通道的输出在这个操作中被“掩码”。掩码中的0表示该通道被掩码,因此其值不会被向量操作的结果覆盖。如果操作中没有指定掩码,则没有通道被掩码。(注意,这相当于提供一个全1的掩码。)
提示: 你的解决方案将需要使用多个掩码寄存器和库中提供的各种掩码操作。 - 提示: 使用
_cs149_cntbits函数在这个问题中很有用。 - 考虑如果循环迭代总数不是SIMD向量宽度的倍数会发生什么。我们建议你用
./myexp -s 3测试你的代码。提示: 你可能会发现_cs149_init_ones有用。 - 提示: 使用
./myexp -l在最后打印执行的向量指令日志。使用函数addUserLog()在日志中添加自定义调试信息。随意添加额外的CS149Logger.printLog()来帮助你调试。
程序的输出将告诉你你的实现是否生成了正确的输出。如果有不正确的结果,程序会打印出它找到的第一个,并打印出函数输入和输出的表格。你的函数的输出在“output =”之后,应该与“gold =”之后的结果匹配。程序还会打印出描述CS149伪向量单元利用率的统计信息。你应该将“总向量指令”值视为你实现的性能指标。(你可以假设每个CS149伪向量指令在CS149伪SIMD CPU上需要一个周期。)“向量利用率”显示启用的向量通道的百分比。
你需要做的是:
- 在
clampedExpVector中实现clampedExpSerial的向量化版本。你的实现应该适用于任意组合的输入数组大小(N)和向量宽度(VECTOR_WIDTH)。 - 运行
./myexp -s 10000并扫过向量宽度从2、4、8到16。记录得到的向量利用率。你可以通过更改CS149intrin.h中的#define VECTOR_WIDTH值来实现这一点。向量利用率随着VECTOR_WIDTH的变化是增加、减少还是保持不变?为什么? - 额外奖励:(1分) 在
arraySumVector中实现arraySumSerial的向量化版本。你的实现可以假设VECTOR_WIDTH是输入数组大小N的因数。虽然顺序实现运行在O(N)时间内,但你的实现应该旨在达到(N / VECTOR_WIDTH + VECTOR_WIDTH)或甚至(N / VECTOR_WIDTH + log2(VECTOR_WIDTH))的运行时间。你可能会发现hadd和interleave操作有用。
我的实现
(1)
clampedExpVector 代码:
1 | void clampedExpVector(float* values, int* exponents, float* output, int N) { |
(2)
执行./myexp -s 10000 (Exp的长度为 10000)
向量利用率 随 VECTOR_WIDTH 变化图表:
| 向量宽度 | 2 | 4 | 8 | 16 |
|---|---|---|---|---|
| 向量利用率 | 90.1% | 85.8% | 83.7% | 82.6% |
向量利用率随向量宽度的增加而减小。
原因:
寄存器资源限制:在 SIMD 编程中,每个处理器核心都有固定数量的向量寄存器。当向量宽度增加时,需要更多的寄存器资源来存储更宽的向量。如果寄存器资源不足,就会限制向量指令的并行度,降低向量利用率。
内存访问效率下降:较宽的向量需要更多的内存带宽来加载和存储数据。如果内存带宽不足,就会导致内存访问延迟,降低向量指令的吞吐量,从而降低向量利用率。
控制流复杂度增加:宽向量可能需要更复杂的控制流和地址计算逻辑,增加了指令派发和执行的开销,降低了向量利用率。
不可向量化的代码比例增加:当向量宽度增加时,通常会有更多的不可向量化代码(如边界条件处理、数据依赖等),占用了处理器资源,降低了向量利用率。
程序 3:使用 ISPC 并行生成分形图像(20 分)
既然你已经熟悉了 SIMD 执行,我们将返回到并行 Mandelbrot 分形图像生成(类似于程序 1)。和程序 1 一样,程序 3 计算 Mandelbrot 分形图像,但它通过利用 CPU 的四个核心和每个核心内的 SIMD 执行单元,实现了更大的加速效果。
在程序 1 中,你通过为系统中的每个处理核心创建一个线程来并行化图像生成。然后,你将部分计算分配给这些并发执行的线程。(由于在程序 1 中线程与处理核心是一对一的,因此你实际上是显式地将工作分配给核心。)程序 3 使用 ISPC 语言构造来描述独立计算,而不是指定并发执行线程的具体映射。这些计算可以并行执行,而不会违反程序的正确性(实际上它们确实会并行执行!)。在 Mandelbrot 图像的情况下,计算每个像素的值是一个独立的计算。通过这些信息,ISPC 编译器和运行时系统负责生成一个程序,该程序尽可能高效地利用 CPU 的并行执行资源集合。
你需要对由 C++ 和 ISPC 组合编写的程序 3 进行一个简单的修复(错误导致性能问题,而不是正确性问题)。通过正确的修复,你应该会观察到性能比原始的 mandelbrotSerial() 串行 Mandelbrot 实现高出 32 倍以上。
程序 3,第 1 部分:一些 ISPC 基础知识(20 分中的 10 分)
阅读 ISPC 代码时,你必须记住,尽管代码看起来很像 C/C++ 代码,但 ISPC 执行模型与标准的 C/C++ 不同。与 C 相比,ISPC 程序的多个程序实例始终在 CPU 的 SIMD 执行单元上并行执行。并发执行的程序实例数量由编译器确定(并为底层机器专门选择)。这个并发实例数可以通过内置变量 programCount 获得。ISPC 代码可以通过内置的 programIndex 引用其自己的程序实例标识符。因此,从 C 代码调用 ISPC 函数可以被认为是生成了一组并发的 ISPC 程序实例(在 ISPC 文档中称为 gang)。这组实例运行到完成,然后控制权返回给调用的 C 代码。
停下。这是你友好的导师。请再读一遍上段文字。相信我。
作为示例,以下程序使用常规 C 代码和 ISPC 代码的组合来相加两个 1024 元素的向量。正如我们在课堂上讨论的那样,由于 gang 中的每个实例都是独立的,并且执行完全相同的程序逻辑,因此可以通过使用 SIMD 指令实现加速。
下面是一个简单的 ISPC 程序。以下 C 代码将调用以下 ISPC 代码:
------------------------------------------------------------------------
C 程序代码: myprogram.cpp
------------------------------------------------------------------------
const int TOTAL_VALUES = 1024;
float a[TOTAL_VALUES];
float b[TOTAL_VALUES];
float c[TOTAL_VALUES]
// 初始化数组 a 和 b。
sum(TOTAL_VALUES, a, b, c);
// 在 sum 返回后,a + b 的结果存储在 c 中。
对应的 ISPC 代码:
------------------------------------------------------------------------
ISPC 代码: myprogram.ispc
------------------------------------------------------------------------
export sum(uniform int N, uniform float* a, uniform float* b, uniform float* c)
{
// 假设 programCount 可以整除 N。
for (int i=0; i<N; i+=programCount)
{
c[programIndex + i] = a[programIndex + i] + b[programIndex + i];
}
}
上述 ISPC 程序代码在程序实例之间交错处理数组元素。注意与程序 1 的相似之处,在程序 1 中,你静态地将图像部分分配给线程。
然而,与其考虑如何在程序实例之间划分工作(即如何将工作映射到执行单元),通常更方便、更强大的是仅关注问题的独立部分划分。ISPC 的 foreach 构造提供了一种表达问题分解的机制。下面,ISPC 函数 sum2 中的 foreach 循环定义了一个迭代空间,其中所有迭代都是独立的,因此可以按任何顺序执行。ISPC 处理将循环迭代分配给并发程序实例。下面是 sum 和 sum2 之间的区别,尽管微妙但非常重要。sum 是命令式的:它描述了如何将工作映射到并发实例。下面的示例是声明式的:它仅指定要执行的工作集。
-------------------------------------------------------------------------
ISPC 代码:
-------------------------------------------------------------------------
export sum2(uniform int N, uniform float* a, uniform float* b, uniform float* c)
{
foreach (i = 0 ... N)
{
c[i] = a[i] + b[i];
}
}
在继续之前,建议你通过阅读 ISPC 示例演练来熟悉 ISPC 语言构造,该演练可在 http://ispc.github.io/example.html 找到。演练中的示例程序与 mandelbrot.ispc 中 mandelbrot_ispc() 的程序 3 实现几乎完全相同。在作业代码中,我们更改了 foreach 循环的界限,以便实现更直接的实现。
你需要做的是:
- 编译并运行 mandelbrot ispc 程序。ISPC 编译器当前配置为发出 8 宽 AVX2 向量指令。 鉴于你对这些 CPU 的了解,你期望的最大加速是多少?为什么你观察到的数字可能低于这个理想值?(提示:考虑你正在执行的计算的特征?描述图像的哪些部分对 SIMD 执行提出了挑战?比较渲染 Mandelbrot 集的不同视图的性能可能有助于确认你的假设。)
我们提醒你,对于本节描述的代码,ISPC 编译器将程序实例的 gang 映射到单个核心上执行的 SIMD 指令。这种并行化方案不同于程序 1,其中通过在多个核心上运行线程来实现加速。
如果你查阅有关 myth 机器中 CPU 的详细技术资料,你会发现关于每个时钟周期可以运行多少标量和向量指令的规则非常复杂。对于本作业,你可以假设浮点数学的标量执行单元和 8 宽向量执行单元数量大致相同。
我的实现
(1)ISPC 编译器被配置为发出 8 宽 AVX2 向量指令。这意味着它可以同时对 8 个浮点数执行相同的操作,从而理论上可以获得 8 倍的加速。
编译并运行 mandelbrot ispc 程序

图一加速比为3.54,图二加速比为2.86
低于理想值的原因:
这是由于同一条AVX2指令的车道上的不平衡计算造成的,即图片中的黑白过渡部分。比较两个视图,可能会在视图2中发现更多的“白色分支”,这会导致更差的性能。
程序 3,第 2 部分:ISPC 任务(20 分中的 10 分)
ISPC 的 SPMD 执行模型和类似 foreach 的机制促进了利用 SIMD 处理的程序的创建。该语言还提供了一种额外的机制,利用多个核心进行 ISPC 计算。该机制是启动 _ISPC 任务_。
参见函数 mandelbrot_ispc_withtasks 中的 launch[2] 命令。该命令启动了两个任务。每个任务定义了一个将由一组 ISPC 程序实例执行的计算。根据函数 mandelbrot_ispc_task,每个任务计算最终图像的一个区域。类似于 foreach 构造定义的循环迭代可以按任何顺序执行(并且可以由 ISPC 程序实例并行处理),由此启动的任务可以按任何顺序处理(并且可以在不同的 CPU 核心上并行处理)。
你需要做的是:
- 使用参数
--tasks运行mandelbrot_ispc。在视图 1 上你观察到的加速是多少?与未将计算划分为任务的mandelbrot_ispc版本相比,加速是多少? - 通过更改代码中
mandelbrot_ispc_withtasks()函数内的任务数,有一种简单的方法可以提高mandelbrot_ispc --tasks的性能。通过仅更改mandelbrot_ispc_withtasks()函数中的代码,你应该能够实现比串行版本的代码超过 32 倍的性能。你是如何确定要创建多少个任务的?为什么你选择的数字效果最好? - 额外奖励:(2 分) 线程抽象(在程序 1 中使用)和 ISPC 任务抽象之间有什么区别?(创建/连接)机制和(启动/同步)机制在语义上有一些明显的区别,但这些区别的影响更加微妙。以下是指导你回答的一个思维实验:当你启动 10,000 个 ISPC 任务时会发生什么?当你启动 10,000 个线程时会发生什么?(对于此思维实验,请在一般情况下讨论——即不要将讨论与给定的 Mandelbrot 程序联系起来。)
_聪明学生的问题_:嘿,等等!为什么 ISPC 系统有两种不同的机制(foreach 和 launch)来表达独立的、可并行化的工作?系统不能只是将 foreach 的许多迭代划分到所有核心,并且还发出适当的核心 SIMD 代码吗?
_回答_:好问题!答案有很多种可能。来参加我的办公时间讨论吧。
我的实现
(1)使用参数 –task 运行:

未划分:加速比为3.54
划分后:加速比为6.94
(2)
我根据机器可以提供的最大超线程数来确定任务的数量。我的电脑可以支持16个超线程,所以取任务数为16可以取得最好的成绩。

程序 4:迭代 sqrt(15 分)
程序 4 是一个 ISPC 程序,它计算 2000 万个在 0 到 3 之间的随机数的平方根。它使用一种快速的迭代实现的平方根方法,使用 Newton 方法来求解方程 ${\frac{1}{x^2}} - S = 0$。该实现使用 1.0 作为初始猜测值。下图显示了对于(0-3)范围内的值,sqrt 收敛到准确解所需的迭代次数。(对于此范围之外的输入值,实现不收敛)。注意收敛速度取决于初始猜测的准确性。
注意:这个问题是一个复习,以双重检查你的理解,因为它涵盖了与程序 2 和程序 3 类似的概念。
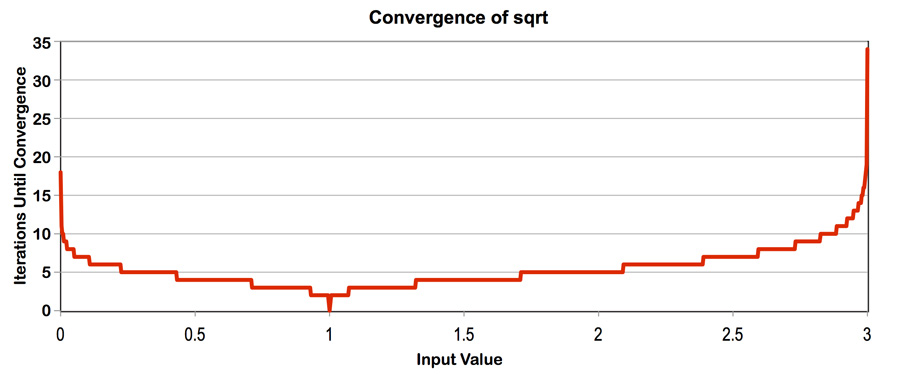
你需要做的是:
- 构建并运行
sqrt。报告单个 CPU 核心(无任务)和使用所有核心(有任务)时的 ISPC 实现加速。 SIMD 并行化的加速是多少?多核心并行化的加速是多少? - 修改数组值的内容以提高 ISPC 实现的相对加速。构造一个特定输入,__最大化相对于代码的串行版本的加速__,并报告实现的加速结果(对于有任务和无任务的 ISPC 实现)。你的修改是否提高了 SIMD 加速?是否提高了多核心加速(即从无任务的 ISPC 到有任务的 ISPC 的好处)?请解释为什么。
- 构造一个特定的
sqrt输入,__最小化 ISPC(无任务)相对于代码的串行版本的加速__。描述此输入,描述你选择它的原因,并报告 ISPC 实现的相对性能。效率下降的原因是什么?
__(请记住我们使用的是--target=avx2选项为 ISPC 生成 8 宽 SIMD 指令)__。 - 额外奖励:(最多 2 分) 使用 AVX2 内联函数手动编写你自己的
sqrt函数版本。为了获得奖励,你的实现应接近 ISPC 生成的二进制文件的速度(或更快)。你可能会发现 Intel 内联函数指南 非常有帮助。
我的实现
(1)运行代码:

无任务时ISPC: 3.75加速比
有任务时ISPC: 45.53加速比
SIMD并行化带来了3.75倍的加速,多核并行化带来了12.14倍的加速。
(2)我构造了一个所有元素都等于2.998的数组。由于所有元素都是相等的,因此每个通道都需要相同的迭代,从而导致SIMD并行化中的无掩码。此外,2.998需要更多的计算,这将使CPU饱和,并补偿任务版本中的多线程开销。
运行代码结果:

我从ISPC获得了4.15倍的加速,从任务ISPC获得了41.96倍的加速。
(3)我构造了一个数组,除了索引为8的倍数等于2.998的元素外,所有元素都等于1。
运行结果:

对于这个输入,我从ISPC获得了0.55倍的加速,这比串行情况更糟糕。
程序 5:BLAS 的 saxpy(10 分)
程序 5 是 BLAS(Basic Linear Algebra Subproblems)库中 saxpy 例程的实现,在许多系统上被广泛使用(并进行了大量优化)。saxpy 计算简单的操作 result = scale*X+Y,其中 X、Y 和 result 是 N 元素的向量(在程序 5 中,N = 2000 万),而 scale 是一个标量。注意,saxpy 对于每三个元素使用的操作是两个数学运算(一个乘法,一个加法)。saxpy 是一个 可轻松并行化的计算,具有可预测的、规则的数据访问和可预测的执行成本。
你需要做的是:
- 编译并运行
saxpy。程序将报告使用 ISPC(无任务)和 ISPC(有任务)实现的 saxpy 的性能。你观察到使用带有任务的 ISPC 的加速是多少?解释该程序的性能。你认为它可以显著改进吗?(例如,你能重写代码以实现近似线性的加速吗?是或否?请解释你的答案。) - 额外学分:(1 分) 请注意,
main.cpp中计算的总内存带宽是TOTAL_BYTES = 4 * N * sizeof(float);。即使saxpy从 X 加载一个元素,从 Y 加载一个元素,并将一个元素写入result,乘以 4 也是正确的。为什么会这样?(提示,思考 CPU 缓存的工作原理。) - 额外学分:(每种情况视情况而定) 提高
saxpy的性能。我们希望这里的加速比大约为 2.1 倍或更高(即 $\frac{旧运行时}{新运行时} >= 2.1$)。请解释你是如何达到解决方案的,以及你的最终解决方案是什么,以及相关的加速。此过程的撰写应描述一系列步骤。我们期望得到的是”我测量了……,这让我相信 X。所以为了改进,我尝试了……,导致了速度提升/减慢……”的形式。
注意:一些学生在过去的问题中陷入了困境(想得太多)。我们期望得到一个简单的答案,但是从运行这个问题的结果中可能会引发更多的问题。我们鼓励你与工作人员交流。
我的实现
(1)编译运行:

通过使用任务,我只获得了1.78倍的加速。由于这个程序需要很多内存访问,所以它受到内存带宽的限制。我认为它不可能有实质性的改善。
(2)当程序写入result的一个元素时,它首先将包含该元素的缓存行取出到缓存中。这需要一个内存操作。然后当这个缓存行不需要时,它将从缓存中取出来,这需要另一个内存操作。
程序 6:加速 K-Means(15 分)
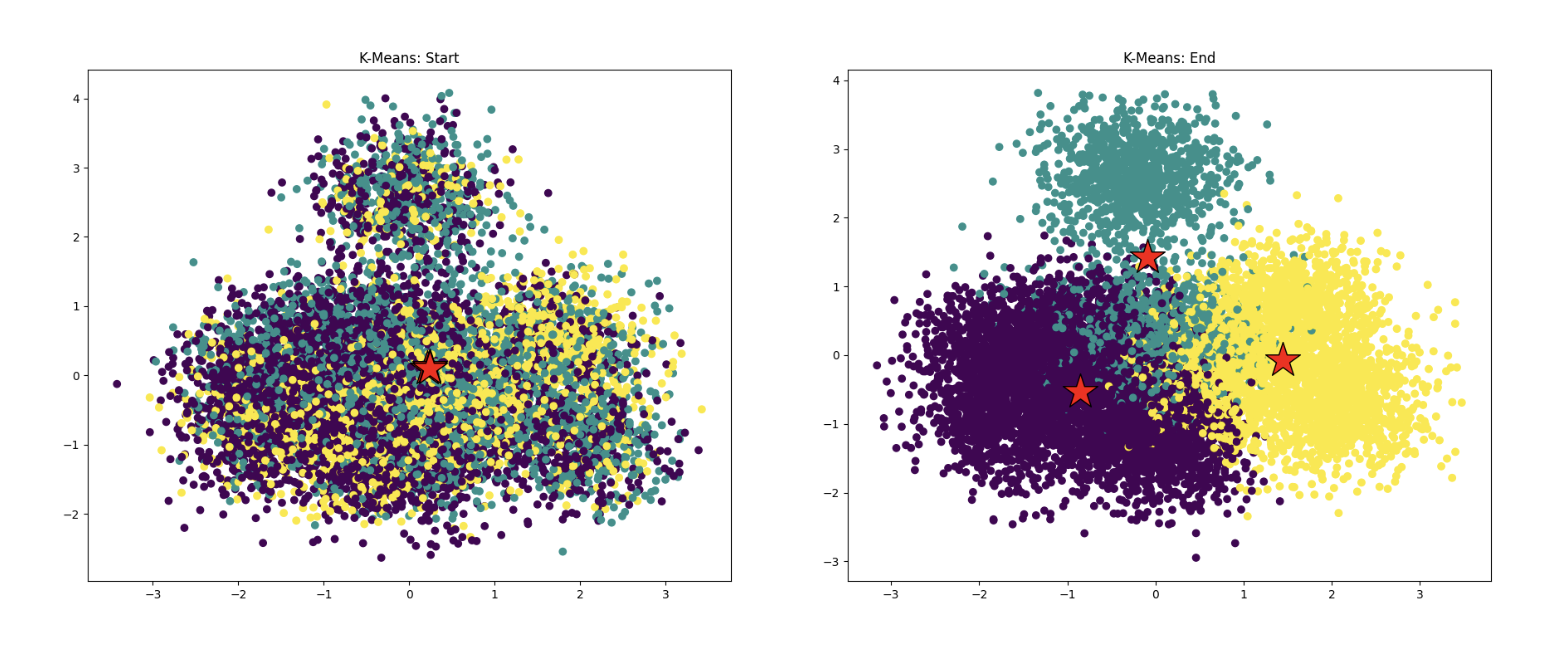
程序 6 使用 K-Means 数据聚类算法(维基百科,CS 221 手册)对一百万个数据点进行聚类。如果你对算法不熟悉,不用担心!对于这个练习来说,具体内容并不重要,但是在高层次上,给定 K 个起始点(聚类中心),该算法迭代地更新聚类中心直到满足收敛条件。结果可以在下面的图像中看到,显示了程序在算法开始和结束时的状态,其中红色星号是聚类中心,数据点颜色对应于聚类分配。
在起始代码中,你已经得到了 K-means 算法的正确实现,但在当前状态下,它的速度不如我们希望的快。这就是你的任务!你的工作是弄清楚代码中哪里需要改进以及如何改进。你将练习的关键技能是__定位性能瓶颈__。我们不会告诉你在代码中应该查找哪里。你需要自己找到。你的第一个想法应该是……代码中的时间花在哪里?你应该在源代码中插入计时代码来进行测量。根据这些测量结果,你应该关注花费大部分运行时间的代码部分,并仔细了解它,以确定是否有方法可以加速它。
你需要做的是:
使用命令
ln -s /afs/ir.stanford.edu/class/cs149/data/data.dat ./data.dat在当前目录中创建到数据集的符号链接(确保你在prog6_kmeans目录中)。这是一个大文件(~800MB),所以这是访问它的首选方式。但是,如果你想要一个本地副本,你可以在个人计算机上运行这个命令scp [Your SUNetID]@myth[51-66].stanford.edu:/afs/ir.stanford.edu/class/cs149/data/data.dat ./data.dat。一旦你有了数据,编译并运行kmeans(第一次尝试加载数据可能需要更长的时间)。程序将报告算法在数据上的总运行时间。运行
pip install -r requirements.txt下载必要的绘图包。接下来,尝试运行python3 plot.py,它将从运行kmeans生成的日志(”start.log” 和 “end.log”)生成文件 “start.png” 和 “end.png”。这些文件将在当前目录中,并且应该与上面的图像类似。只要聚类看起来“合理”(使用起始代码生成的图像作为参考),并且大多数数据点似乎被分配给最近的聚类中心,代码就保持正确。利用
common/CycleTimer.h中的计时函数确定代码中存在哪些性能瓶颈。你需要调用CycleTimer::currentSeconds(),它返回当前时间(以秒为单位)作为浮点数。在代码的哪些部分花费了大部分时间?根据前一步的发现改进实现。我们希望实现的加速比约为 2.1 倍或更高(即 $\frac{旧运行时}{新运行时} >= 2.1$)。请解释你是如何达到解决方案的,以及你的最终解决方案是什么,以及相关的加速。此过程的撰写应描述一系列步骤。我们期望得到的是“我测量了……,这让我相信 X。所以为了改进,我尝试了……,导致了速度提升/减慢……”的形式。
约束:
- 你只能修改
kmeansThread.cpp中的代码。你不允许修改stoppingConditionMet函数,也不能改变kMeansThread的接口,但任何其他操作都可以(例如,你可以向WorkerArgs结构体添加新成员,重写函数,分配新数组等)。然而… - 确保不改变实现的功能!如果算法不收敛或从运行
python3 plot.py生成的结果看起来与起始代码生成的结果不同,那么就有问题! 例如,你不能简单地删除主“while”循环或更改dist函数的语义,因为这将产生不正确的结果。 - 此问题不应需要大量编码。我们的解决方案修改/添加了大约 20-25 行代码。
- 一旦你使用计时器定位了热点,为了改进代码,请确保你理解了 K、M 和 N 的相对大小。
- 试着优先考虑具有高回报潜力的代码改进,并思考问题中可用的不同并行性轴,以及如何利用它们。
这个问题的目标是让你练习如何对性能导向的程序进行性能分析和调试。即使你没有达到性能目标,如果你在写作中展示出良好/周到的调试技能,你仍然会得到大部分的分数。
我的实现
(1)没有数据集,写不了…………………………….
ARM-based Macs 的情况
对于那些有新的基于 ARM 的苹果笔记本的人,尝试将 ISPC 编译目标更改为 neon-i32x8,并将编译架构更改为 aarch64,在程序 3、4 和 5 中。其他程序只使用 GCC,并应该生成正确的目标。生成一个关于新的基于 ARM 的苹果笔记本上各种程序性能的报告。工作人员对你的发现很感兴趣。你观察到了 SIMD 执行的加速比是多少?那些没有现代 Macbook 的人可以尝试在像 AWS 这样的云提供商上使用基于 ARM 的服务器,尽管这还没有经过工作人员的测试。
对于好奇的人(强烈推荐)
想了解 ISPC 及其创建过程吗?ISPC 的两位创始人之一 Matt Pharr 写了一篇关于其发展历程的 __令人惊叹的博文__,名为 The story of ispc。它真正触及了许多并行系统设计的问题——特别是有限范围与通用编程语言的价值。在我看来,这对于 CS149 的学生来说是必读的!
提交说明
提交将通过 Gradescope 进行。每个小组只需提交一次。但是,请确保将你的合作伙伴的姓名添加到 Gradescope 提交中。在 Gradescope 上,有两个地方需要提交文件:Assignment 1 (Write-Up) 和 Assignment 1 (Code)。
请将以下内容放在 Assignment 1 (Write-Up) 中:
- 你的撰写内容,保存为
writeup.pdf。请确保文档中包含两位组员的姓名和 SUNet ID(如果是两人组)。
请将以下内容放在 Assignment 1 (Code) 中:
- Program 2 中
main.cpp的实现,保存为prob2.cpp。 - Program 6 中
kmeansThread.cpp的实现,保存为prob6.cpp。 - 任何额外的代码,例如因为你尝试了额外的信用分。
Morty
我阐释你的梦